本工作的背景
尾延迟(Tail Latency)在数据中心中一直备受关注。现在,比较复杂的任务多会选择scale out,即被拆解多个部分由多个机器/CPU完成,那么整个任务的时延将由最慢的那个部分决定,也就是说Tail Latency甚至能决定整体系统性能。再者,应用服务的Tail Latency需要控制在一定范围内,才能够为用户提供更好的体验(QoS,如响应延迟)。为关键应用服务保证可控尾延迟的直观想法是预留足够多的计算资源,那么无论是负载workload发生变化,还是其它因素影响,关键应用的尾延迟都可以保证。但是这与数据中心中另一个重要目标(追求更高的资源利用率)相冲突,因为为了尽可能提高资源利用率,我们需要把尽量多的任务放到同一个机器上。如下图所示,同一台机器上往往同时运行Latency-Critical的任务(比如Memcached)和Best-Effort的任务(如后台分析任务,能够充分利用空闲计算资源)。1
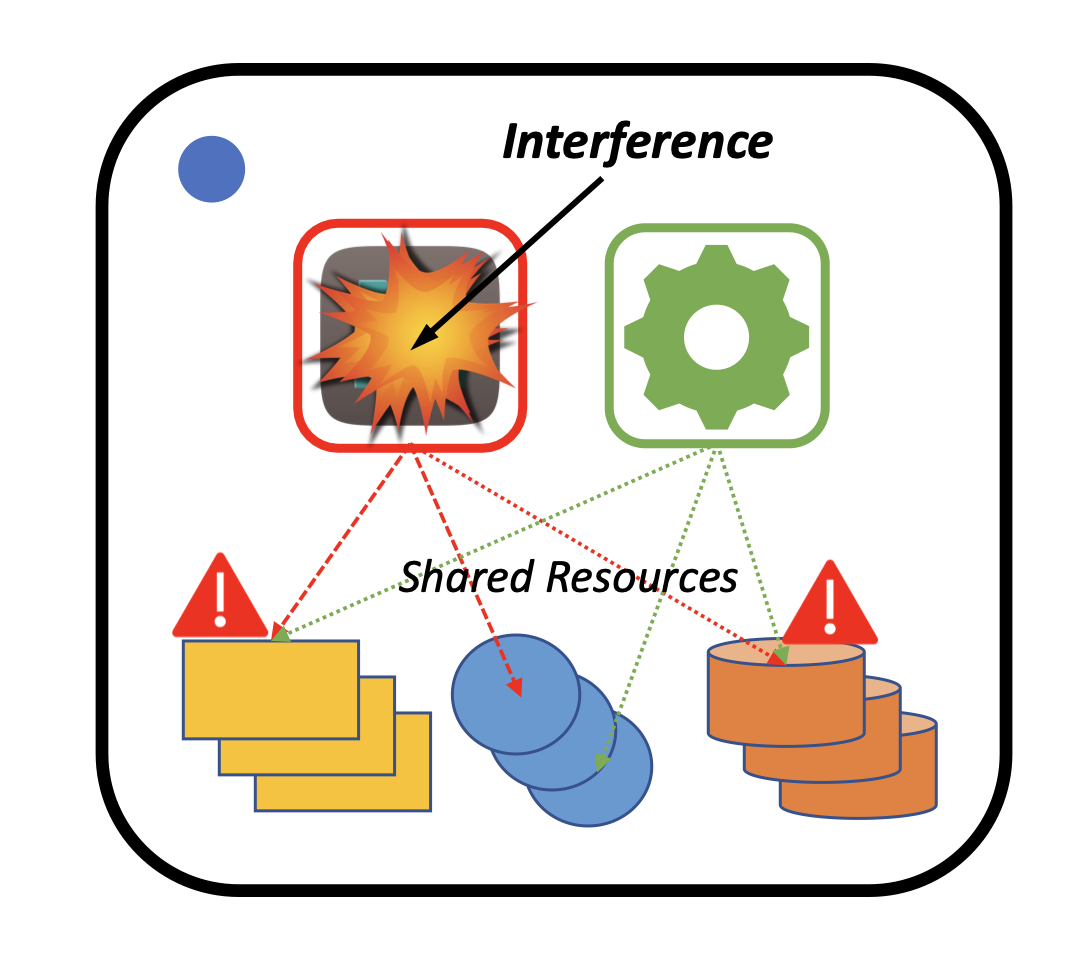
但是,在同一个CPU上运行的任务会共享资源:CPU cores、HyperThread、Caches、内存带宽(bandwidth)等。一旦出现较严重的资源竞争,Latency-Critical的应用将会受到很大的影响(Interference),如Tail Latency突然上升。如果能有效地规避过度的资源竞争,那么问题就能迎刃而解。
本工作的挑战
- 识别干扰源并快速反应:共享 CPU 中存在多种类型的干扰(超线程、内存带宽、LLC 等),并且获得能够在微秒时间尺度上准确检测每种干扰的正确控制信号非常困难。现有系统面临太多的软件开销,无法收集控制信号或快速调整资源分配。
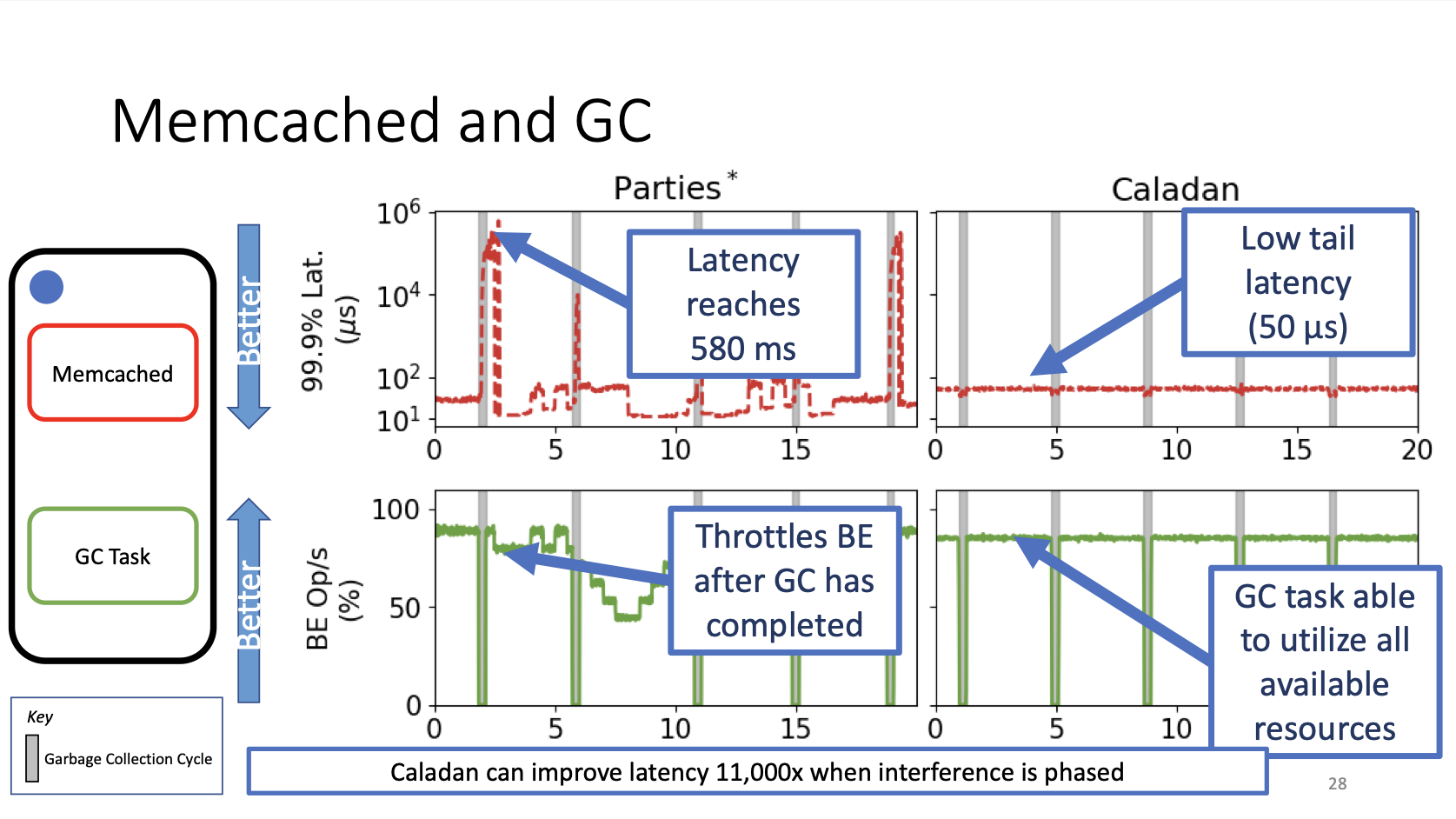
以 Memcached 为例: 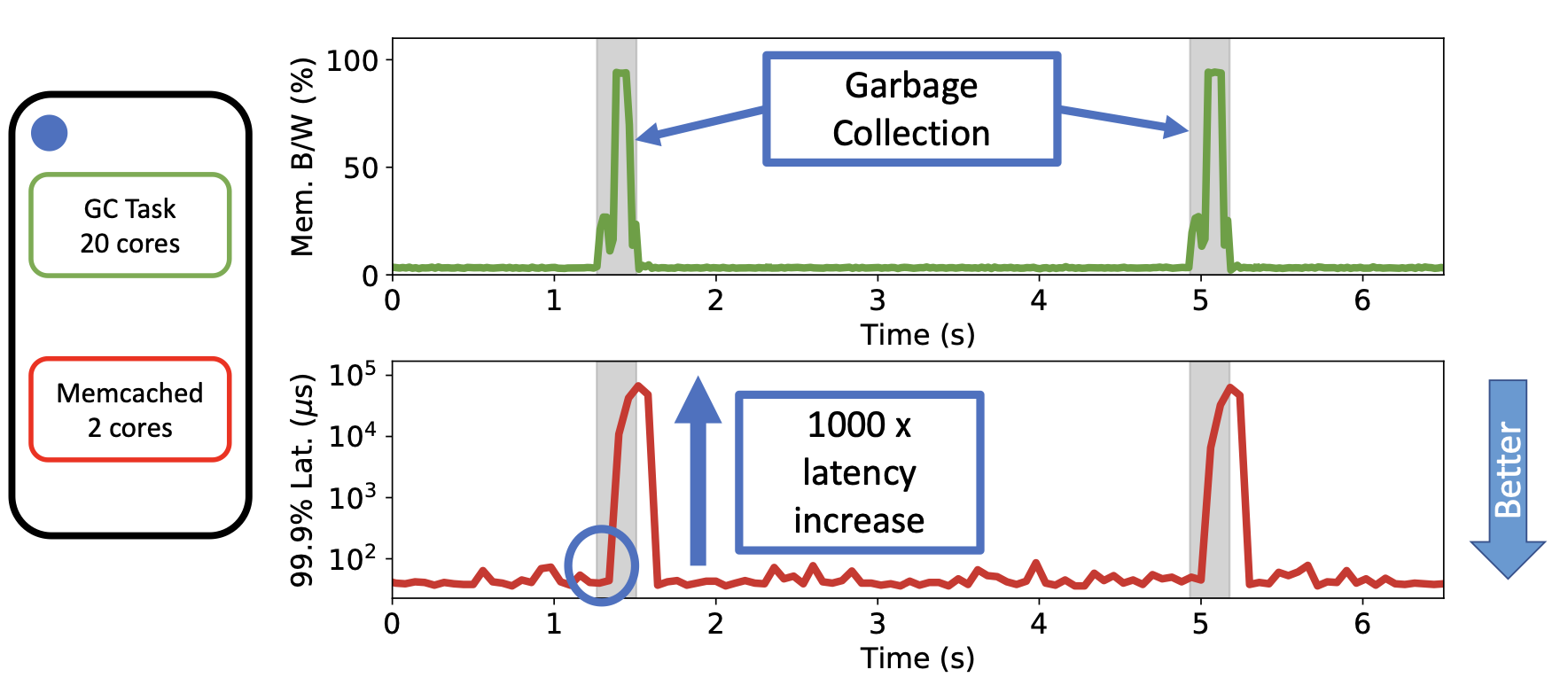
上图给出一个具体的例子:Memcached是Latency Critical(LC)的,GC Task是Best Effort(BE)的。GC任务通常由mark phase和copy phase,在copy phase中GC任务的内存带宽(绿色线)显著上升(持续约100ms)。相应地,Memcached的尾延迟在此期间可能增加1000倍。为了解决这个问题,直观的方法就是在Interference发生之初进行资源的动态分配调整。因此问题的关键转变为如何在足够短的时间内检测到Interference即将发生、以及在足够短的时间内完成资源分配的调整,从而规避严重Interference的发生。现有工作最好也需要花费10s(从Interference开始发生到资源调整结束),在很多情况下(比如上述例子)不能满足需求。
本工作的目标
在保证高资源利用率的同时,严格保证性能隔离。==> 前提要求:在microsecond timescales内检测并解决Interference。
本工作的系统设计
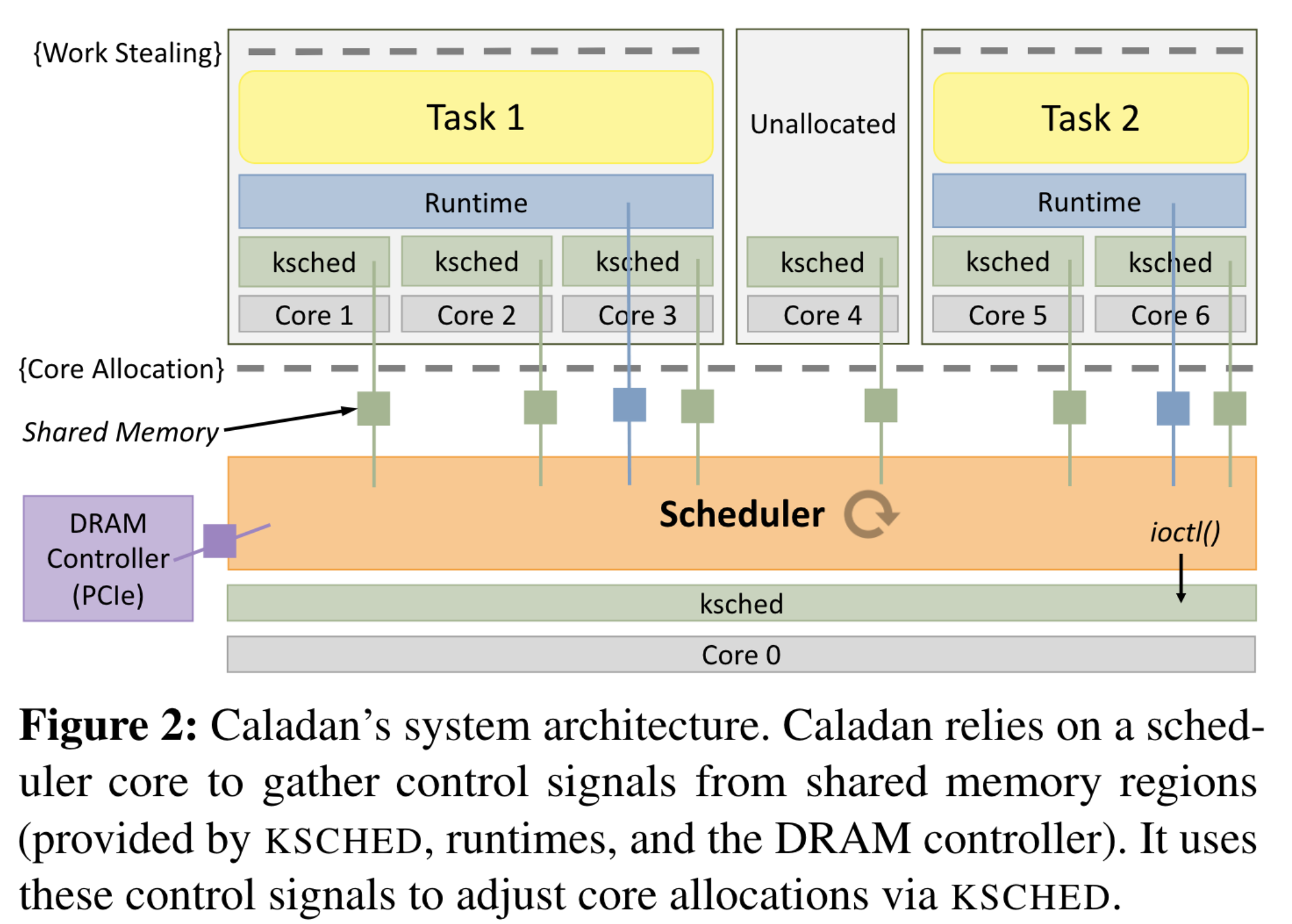
如上图所示,整个系统Caladan包含三个主要部分:
- 橙色的Scheduler: 使用一个单独的CPU core轮询Interference Singals,动态决定其它CPU core的分配。
- 蓝色的Runtime: 用户态库,每一个应用都需要链接这个库。该库提供“绿色”线程(轻量级、用户级线程)和kernel-bypass I/O(网络和存储)。负责使用work stealing来平衡分配给它们的核心之间的负载,并把Interference Singals报告给Scheduer。
- 绿色的ksched: 新增的内核模块,为了更快地完成调度、收集Signal,绕过Linux自带调度。
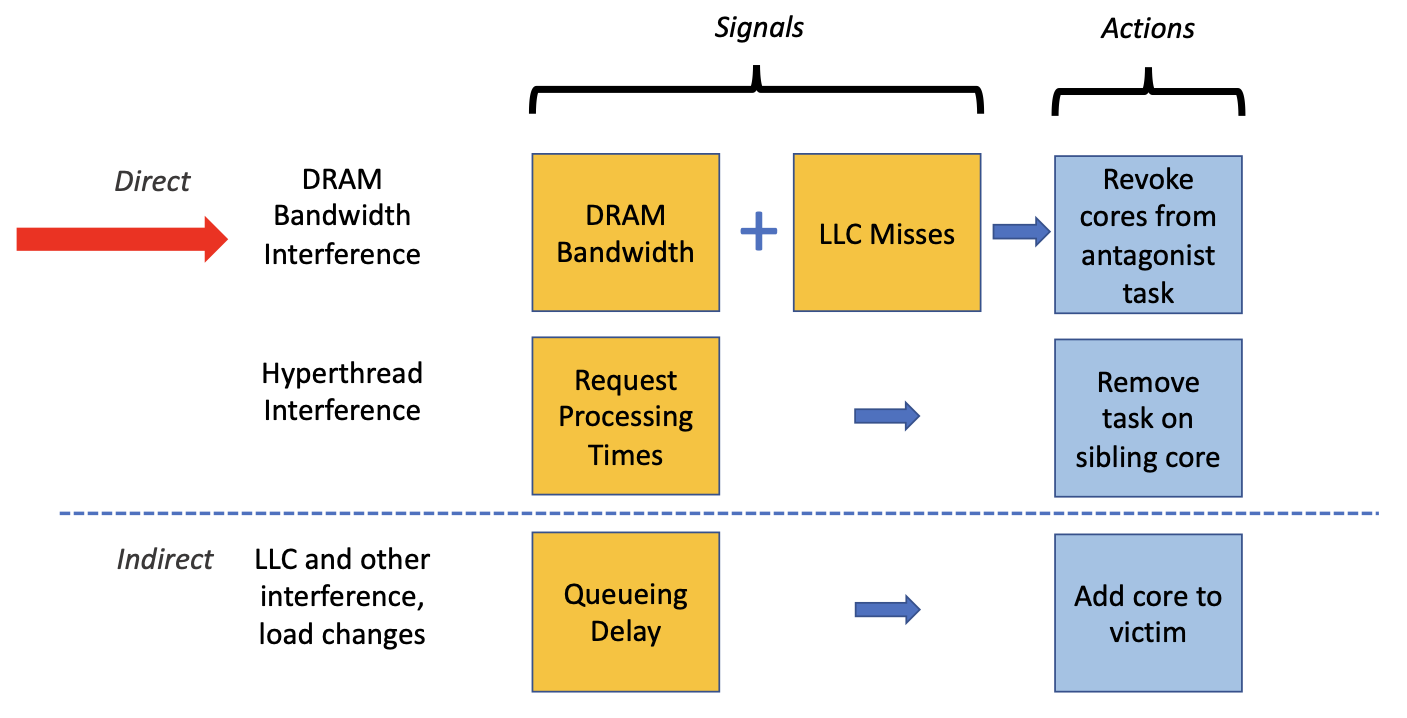
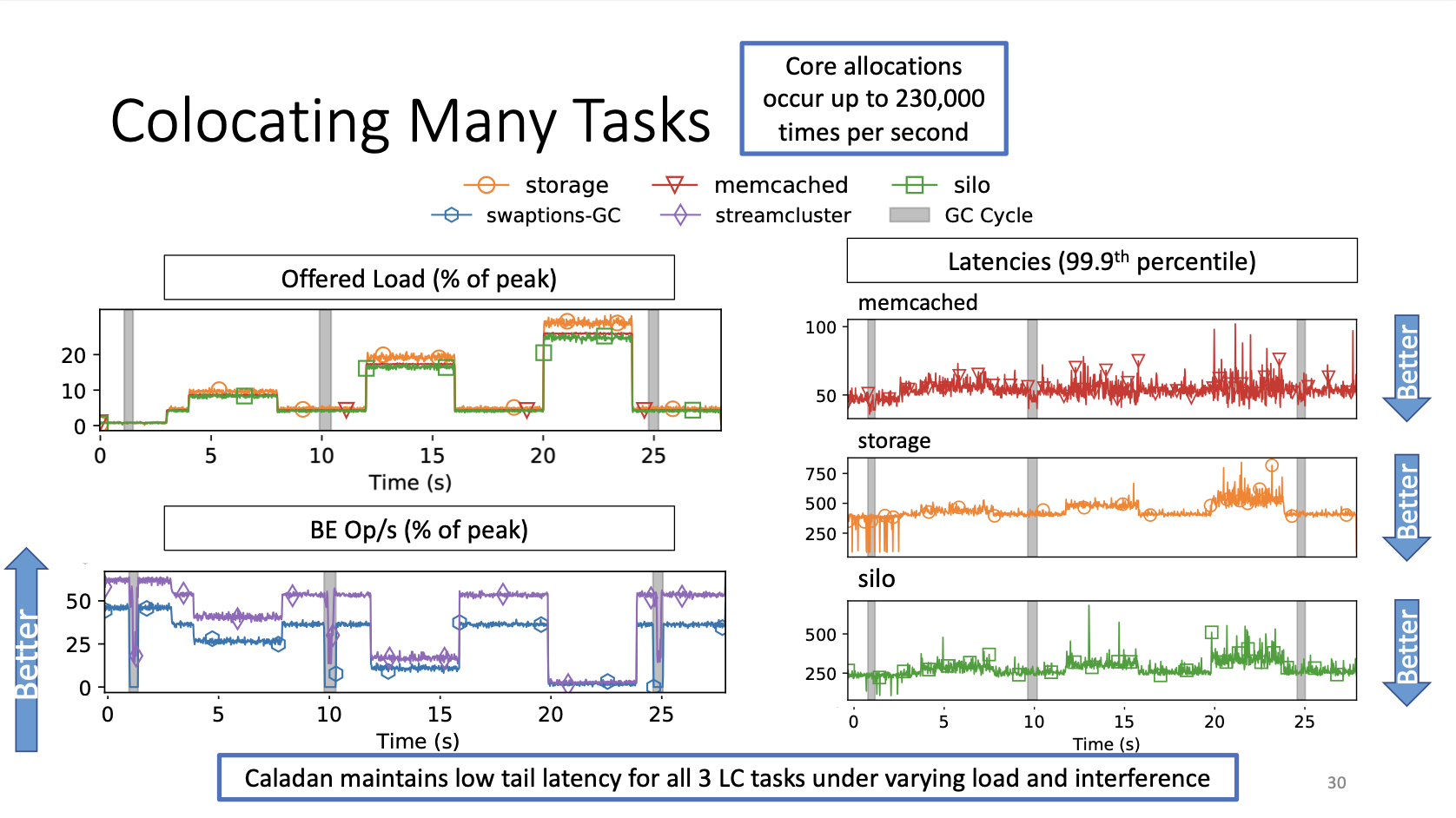
具体来说,Caladan针对性解决上图中所示的三种Interference:内存带宽干扰、超线程干扰、LLC缓存干扰。
- 检测内存带宽干扰发生的Singal:读取全局的DRAM Bandwidth使用信息(硬件支持);通过每个CPU core的LLC miss数量来判断各个core使用的带宽是多少(由ksched协助在每个core上进行统计)。解决方法是从BE Taks收回占用带宽高的CPU core。
- 检测超线程干扰发生的Signal:由Runtime统计Request处理时间是否变长。解决方法是把超线程上的BE Task移除。
- 检测LLC竞争干扰发生的Singal:监测应用程序通过Runtime反应的Queueing Delay。解决方法是通过给LC应用(受到影响的victim)增加CPU core。因为没法简单的避免LLC竞争,所以采取这种间接的解决方式(indrect),期望弥补victim的性能损失(增加并发、缩短Queue)。
本工作的效果